DataSketches 算法概述
在数据领域,有几类经典的查询场景,这些查询在小数据量下很容易做到,但一旦数据量扩大传统思路将变得不可行,必须采用特定的数据结构与算法来支持,这就是今天要讨论的 DataSketches 算法族。
背景
这几类经典的查询场景包括:
- 基数统计 // Unique User or Count Distinct
- 统计某段时间内访问某网站的 UV 数
- 统计某段时间内既访问了页面 A 又访问了页面 B 的 UV 数
- 统计某段时间内访问了页面 A 但未访问页面 B 的 UV 数
- 分位数 // Quantile & Histogram
- 统计某段时间内访问页面 A 与页面 B 各自的等待时长 95 分位数,以及整体等待时长 95 分位数
- TopN 统计 // Most Frequent Items
- 统计某段时间内播放量最多的 10 个视频(热榜列表)
- 随机采样 // Sampling
- 从一个数据流中构造一个大小为 k 的随机样本,无论数据流有多长。
这几类问题在数据量不大的情况下都是非常容易处理的。但一旦数据到达 Billion 量级,常规算法可能要花费数小时甚至数天的时间,并且即使提供充足的计算资源也于事无补,因为这几类问题都难以并行化处理。
DataSketches 就是为了解决大数据场景下的这几类典型问题而诞生的一组算法,最初由雅虎开源。DataSketches 算法以牺牲查询结果的精确性为代价,可以在极小的空间内并行、快速地解决上述几类问题。
核心思想
DataSketches 的字面含义为『数据草图』,其基本思想是把一个源源不断的数据流汇总成一个数据结构,也就是 sketch(草图),之后可以从 sketch 中估算 (evaluate) 出需要的统计信息。
sketch 一般具有以下几个特征:
-
Single-Pass / One-Touch
可以把 sketch 理解为一个状态存储器,它时刻承载着数据流迄今为止的所有历史信息,因此 sketch 通常是 single-pass 的,只需要遍历一遍数据即可取得所需的统计信息。 -
占用空间小
传统的统计方式需要维护一个巨大的数据列表,且随着数据的输入越来越大。sketch 可以在很小的常量空间内摄入海量的数据,通常在 KB 量级。这使得 sketch 在海量数据的统计中非常有优势。

-
可合并性 (mergeability)
这使得 sketch 可以自由地分布式并行处理大量数据,因此具有快速、高效的优势。例如,在统计基数 (Distinct Value) 时,sketch 可以轻易地将局部统计结果合并为全局统计结果,而直接计数则做不到这一点:PS: 第二个式子中的加号代表 sketch 的合并操作。

-
不提供精确的统计值,但可设定误差范围
sketch 为了节省空间必然会丢失一部分信息,因此统计结果不可能是完全精确的。但在现实中,许多分析和决策也并不要求数据是绝对精确的,有时候知道某个统计数据在 1% 的误差范围内往往跟精确的答案一样有效。sketch 可以在计算复杂度与误差之间进行权衡,足以满足大数据场景下大部分的统计需求。一个 sketch 算法的使用流程通常如下(以 HLL 为例):
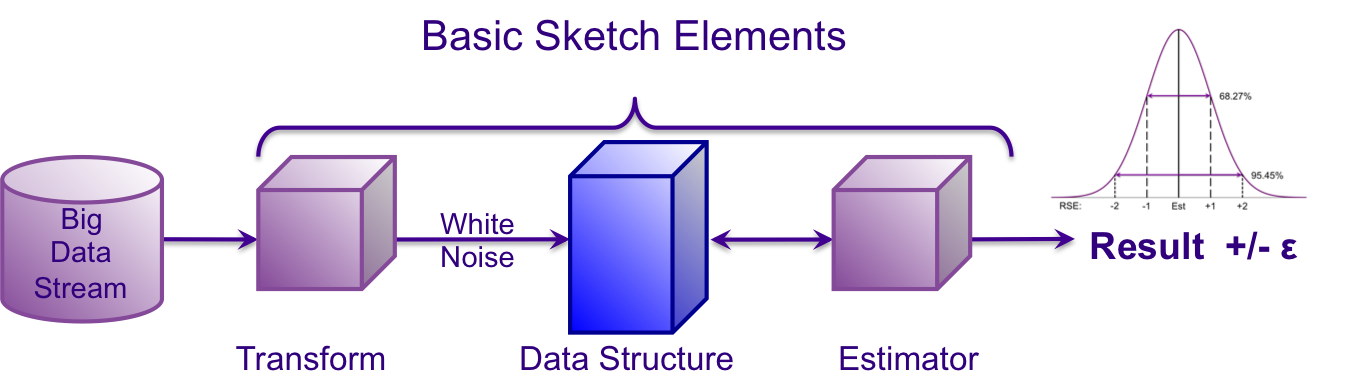
算法一览
基数统计 // Unique User or Count Distinct:
- HLL Sketch(详情参考下一篇博文)
- CPC Sketch
- Theta Sketch
- Tuple Sketch
分位数 // Quantile & Histogram:
TopN 统计 // Most Frequent Items:
- Items Sketch(基于 Misra-Gries 算法)
随机采样 // Sampling:
实际应用
直接使用:
- Hive/Spark (UDXF)
- Druid (Druid DataSketches Extension)
- PostgreSQL (extension)
使用相关算法,但未引用代码库(删除线表示未使用 DataSketch 相关算法):
- ClickHouse (uniq: HLL; quantile: Reservoir Sampling;
topK: Space-Saving) - Doris (approx_count_distinct: HLL;
percentile_approx: T-Digest; topn: Space-Saving) - Redis (
基数统计:1. SCARD-基于集合;2. BITCOUNT-基于bitmap;3. PFCOUNT-HLL。分位数:TDIGEST-基于 T-Digest)